NiFi and Gemini
The blog post introduces Structured Outputs and Batch Inference in Vertex AI / Gemini and discusses how these features can be used in NiFi.
This integration is made possible by the nifi-gemini processors (github), specifically designed to bridge NiFi and Google Vertex AI’s Gemini, making use of the features mentioned above to process batches of records at scale.
End-goal#
Create a recipe website that takes a list of dishes (e.g. Margarita Pizza, Ramen) dynamically generates recipes for each of the dishes using an LLM (Gemini Flash 2.5 in this case).
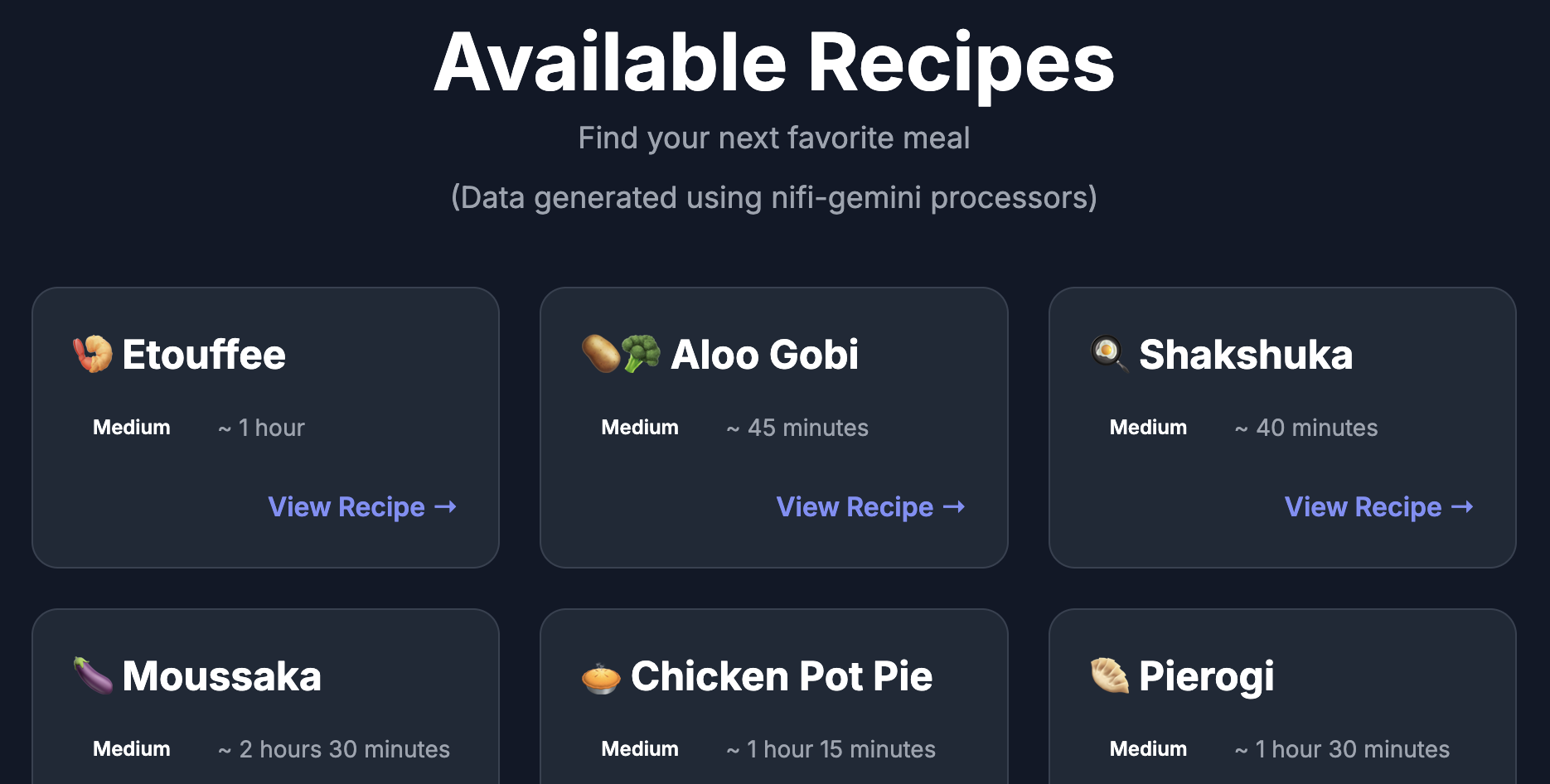
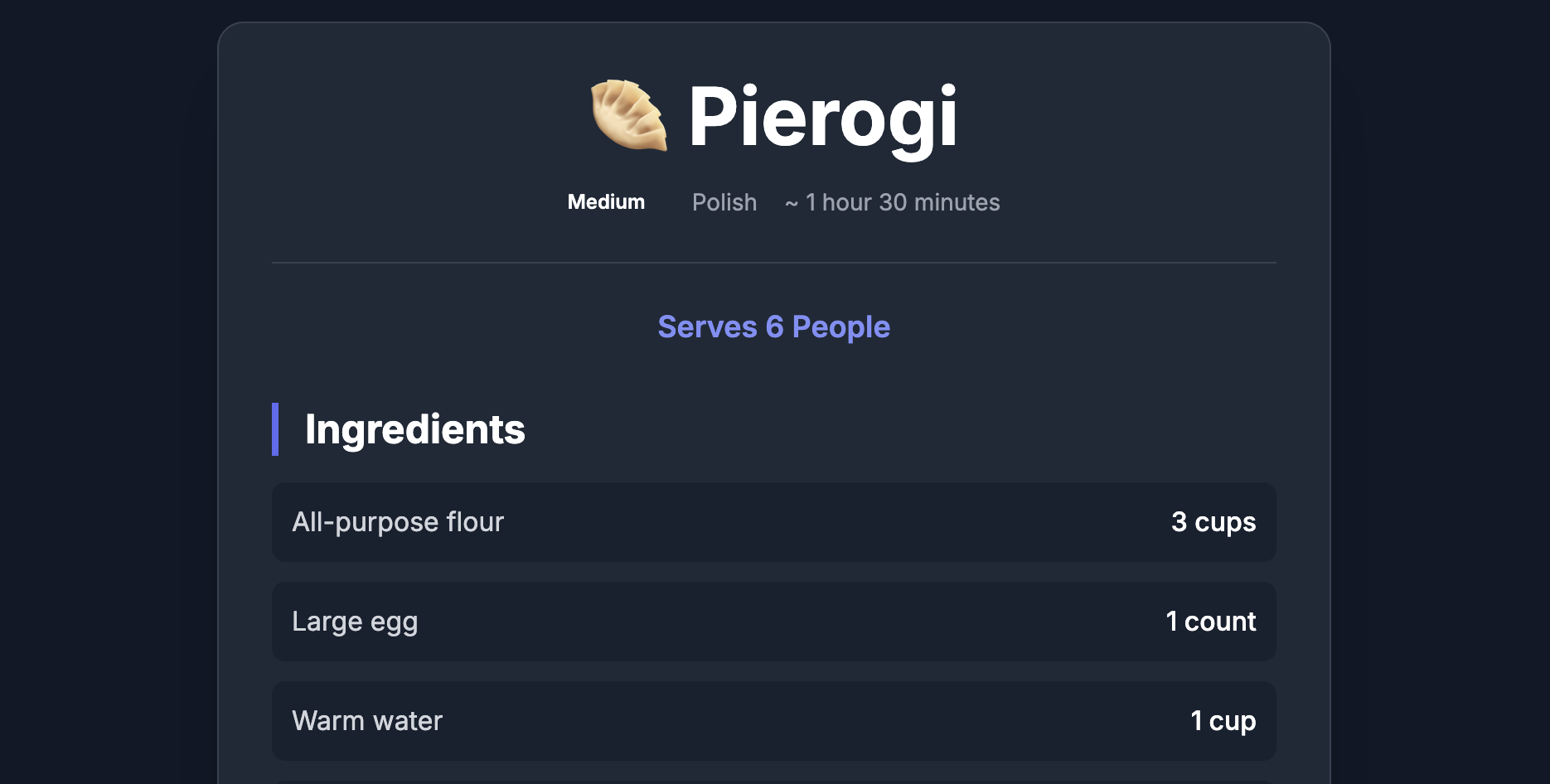
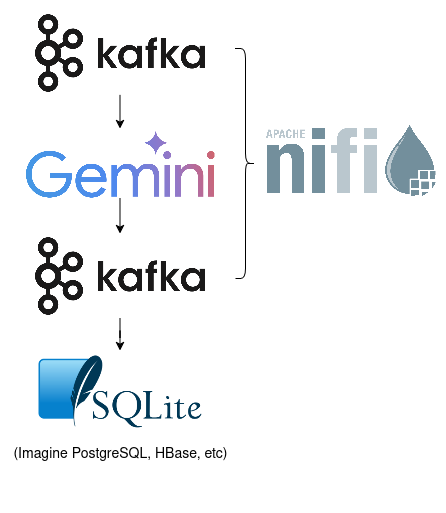
In this example, we’ll use NiFi and Google Vertex AI in the backend to process 1000s of dishes and generate matching recipes.
Introduction#
Structured outputs#
Rightly or wrongly, the rise of Generative AI has been an important focus for investors, management and so on (why walk when you can run).
For the most part, RAG chatbots have made up a big chunk of the proposed use-cases. Chatbots, used in this way, do a decent job of working through unstructured requests, direct from the user, to produce unstructured responses, making use of an unstructured knowledge base.
As integrations with LLMs gets deeper and further away from the end-users, the responses must also become more structured e.g. returning JSON records with pre-defined fields {"locations": ["Hyde Park", ...]} instead of a big text blob _Hyde Park_ is a lovely place to relax in the summer.
I’m sure many people are familiar with prompts that look like this:
Generate a list of parks in London.
Only respond in JSON using a single field locations
that is an array of strings. (please)
Whilst this method does have a surprisingly high-success rate, you are still left praying that the response is valid.
In recognition of this growing requirement, OpenAI and Gemini have both implemented Structured Outputs1.
Structured Outputs allows us to stop begging and praying for LLMs to respond in the way we need it and instead allows us to pre-define a schema for it to follow.
Replacing our prompt above, we can instead require Gemini to respond with the following schema:
{
"type": "object",
"properties": {
"locations": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": ["locations"]
}
Under the covers, this works by token masking – the model is effectively banned from using any tokens that do not follow the schema (e.g. if it has just written {"lo then it’s next token must start with cati. With this method, if we get a response, we can guarantee it is a valid one.
This is huge. Whilst the values in the response may still be total hallucinations, you can at least be sure that those hallucinations are JSON formatted and conform to the schema of your table – step 1 in the move away from user-facing chatbot use-cases.
(Side note: This is similar to how tool execution works in practice.)
Batch inference#
Whilst Structured Outputs are a great step in the right direction, it is still very fiddly (and expensive) to have to stream our requests one-at-a-time when we have to make 1000+ of these requests (e.g. pick out key characters and locations from a list of articles).
Unlike chatbots, if we’re working our way through a bunch of articles or recipes, we don’t need our responses to be as-quick-as-possible. We just need them to finish eventually and be easy to track as they go through.
For use-cases like these, Google Vertex AI’s Batch Inference can be a great fit.
This feature allows you to create a batch of inference requests that are executed asynchronously as a unit. Once completed we can then pull all of our responses out as a complete batch. In our case, we’ll use JSONL files in Google Storage for both in the input and output – not the only option supported.
Benefit of this? Failure modes are simpler which is always good but the main win is that it is currently 50% off when compared to on-demand pricing.2
Using structured outputs in NiFi#
For anyone whose used NiFi for long enough, JSONL files following a predefined schema and processed in a batch, begins to sound suspiciously like a record processor.
Modern NiFi excels whenever you have structured data files (with a well-defined schema) and the need to access external APIs. It allows you to easily create robust no-code data flows and iterate over the flow design rapidly.
nifi-gemini (github) introduces two new processors to NiFi:
- SubmitGeminiBatchRecord
- PollGeminiBatchRecord
SubmitGeminiBatchRecord allows you to take a record-based flowfile in NiFi and use the fields within each record to construct per-record prompts. You must provide an AVRO Schema for the LLM to follow. The resulting prompts for each record in the flowfile are combined together to produce a single Batch Inference request in Google Vertex AI. Optionally, you can also provide a list of string fields that should be returned unchanged by the LLM (invariants e.g. IDs).
PollGeminiBatchRecord can then be used to poll Google Vertex AI for the results of the Batch Inference request. Once successful, this processor returns a JSONL flowfile (one per batch) whose records match the provided schema.
Putting this all into practice#
With the theory out of the way, let’s look at how the use-case discussed at the top of the page could be implemented in NiFi:
NiFi backend for our Recipe website#
In our recipe use-case mentioned at the top of the page, we have the following backend flow in NiFi:
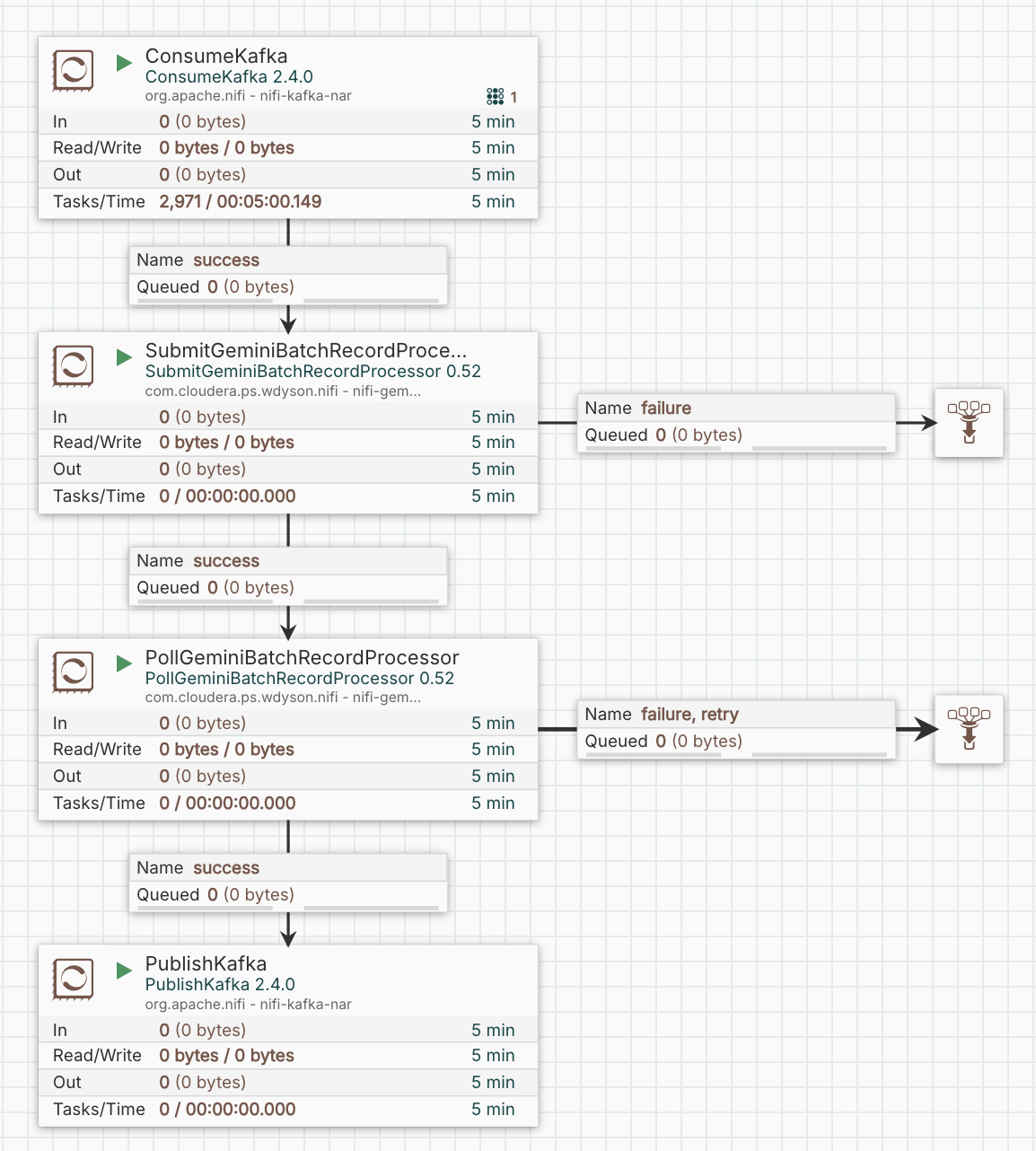
ConsumeKafka and PublishKafka speak for themselves – we consume batches of JSONL records containing the names of dishes that are missing a recipe and produce batches of JSONL records containing the recipes created by Gemini Flash 2.5.
The interesting bit is the piece in the middle.
SubmitGeminiBatchRecord is configured with the following properties (uninteresting properties omitted):
| name | value |
|---|---|
| Record Reader | JsonTreeReader |
| Schema Text | (see below) |
| Prompt | Generate a recipe for ${name} |
| Invariants | id,name |
| GCP Credentials JSON | (not falling for that) |
| id (dynamic) | /id |
| name (dynamic) | /name |
{
"type": "record",
"name": "Recipe",
"namespace": "com.example",
"fields": [
{ "name": "id", "type": "string" },
{ "name": "name", "type": "string" },
{ "name": "difficulty", "type": "string" },
{ "name": "servings", "type": "int" },
{ "name": "cuisine", "type": "string" },
{ "name": "duration", "type": "string" },
{ "name": "ingredients",
"type": {
"type": "array",
"items": {
"type": "record",
"name": "Ingredient",
"fields": [
{ "name": "name", "type": "string" },
{ "name": "unit", "type": "string" },
{ "name": "quantity", "type": "int" }
]
}
} },
{ "name": "steps", "type": { "type": "array", "items": "string" } },
{ "name": "emoji", "type": "string" },
{ "name": "tags", "type": { "type": "array", "items": "string" } }
]
}
(Side note: int turned out to be a poor choice for quantity, can you see why?)
PollGeminiBatchRecord does not have any interesting properties – speaks for itself, it just waits for results (picks up the batch ID from a flowfile attribute). However, you should ensure that retry is enabled for the Retry relationship as this is how the polling mechanism works (seems to take around 5 minutes for small batches i.e. up to 100).
That’s all we need for our backend in NiFi here. As we can see, the business logic here is concentrated around:
- Prompt
- Output Schema (AVRO)
- Invariants
If we really really wanted to add a long backstory to add to our recipes, we’d simply need to add a recipe_backstory field to our schema and the LLM would do the rest:
{ "name": "recipe_backstory", "type": "string" }
Once those have been decided, we’re pretty much finished.
The rest of website#
To pull the results out of Kafka, I created a small Python script that uses the dpkp/kafka-python library to poll our recipe topic for updates, inserting the records verbatim into a SQLite DB as they arrive.
The website itself uses a simple Flask app to show the full list of available recipes, continuing on to link to individual pages containing the details of each individual recipe. (see top of page)
(Side note: The HTML templates themselves both came from Gemini Canvas. Surprisingly good at creating simple self-contained tailwind pages. It’ll use a consistent theme if you generate both pages in a single session.)
Final world#
Whilst RAG chatbots have been a great first step, it is only one of the possible use-cases that leverages LLMs.
With the introduction of structured responses in LLMs, we can start to introduce LLMs further back into the backend where the responses are likely to produce more value. This opens up a lot of potential, without ever needing users to interact directly with an LLM themselves.
Further Examples#
Recipes is just one small example of how NiFi could be used with Vertex AI’s Gemini. A number of other examples can be found on github here.